It’s amazing what spit in a vial can tell you.
When I mailed off the AncestryDNA kit, I figured I already knew the results, barring any family-shattering revelations. (One student I had at Syracuse, a Methodist, told me he turned out to be damn near half Jewish.) I, on the other hand, knew what the thousand-foot view should look like, if not the granular details.
My father has green eyes and sandy hair and, as far as family lore goes, is a British Isles mongrel. My mother is not two full generations out of Mexico; both her paternal and maternal sides are 100% Mexican. On average, Mexicans exhibit a 60/40 ancestral split between Europe and indigenous America (per Analabha Basu et al 2008). So, assuming my mother = 60/40 Spaniard/Amerind split, and assuming my father = 100 Northern European, I assumed, to a rough approximation, that I’d be an 80/20 Euro/Amerind mix. (In the parlance of Oklahomans, I assumed I’d be “1/5 Cherokee”.)
AncestryDNA returned no major surprises. I’m 80% European, 16-19% Amerind.

Paternal.
Mostly Irish, some Scandinavian, trace amounts of British/W. European.
Quite surprised at how Irish the results say I am. I assumed plenty of English, plus a wonderfully American smattering of other Northern, Western, and Central European ancestral regions. I assumed wrongly.
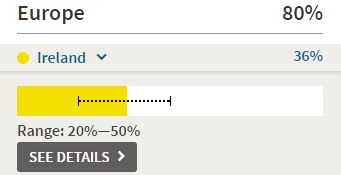
23andMe does not differentiate between English and Irish, but according to AncestryDNA’s white paper, their reference panel is thus differentiated. Here’s the PCA for their European reference panel.
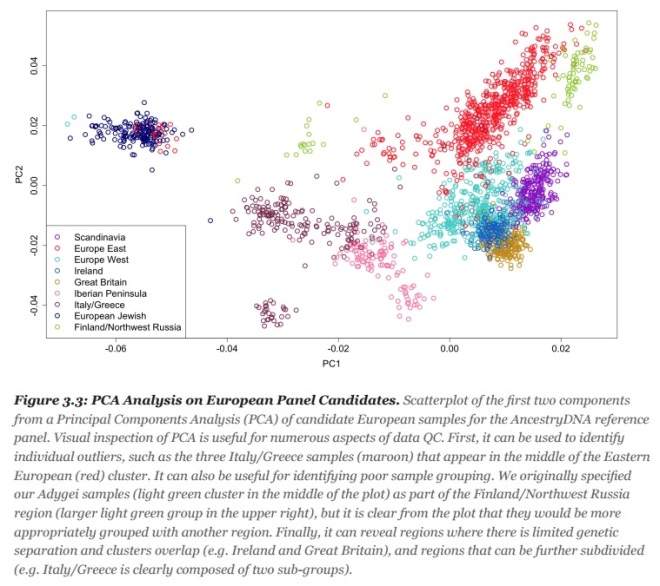
The dark blue/orange cluster is the Irish/English cluster. They’re damn close but distinct enough. In fact, according to the same white paper, Ancestry’s methods have an 80+% accuracy rate for correctly putting the Irish in Ireland (their methods are actually not great at differentiating England and Western Europe).
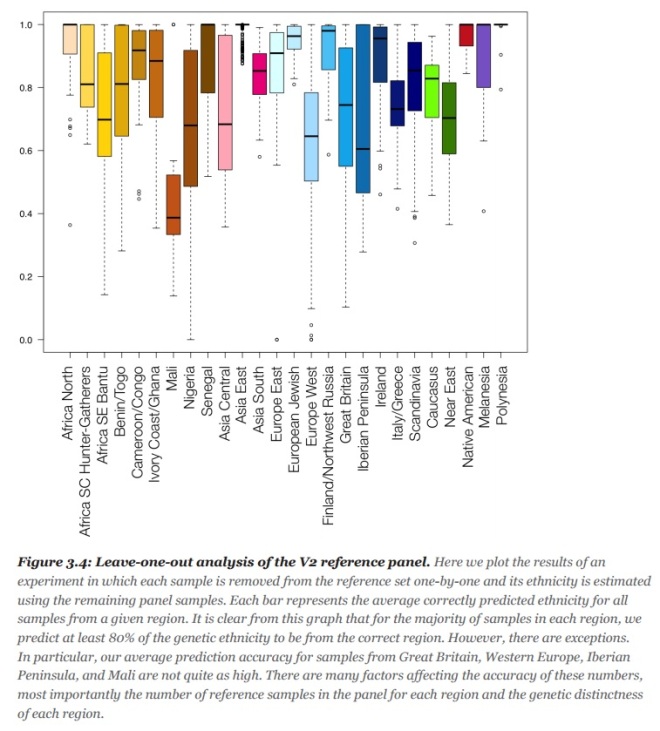
Note: In bar graph above, the shorter the bar, the better the predictive accuracy.
Interesting genetic detail. Irish! In my opinion, however, AncestryDNA’s “Irish” ancestral region should be labeled the “Celtic” ancestral region, for it also includes Scotland, Wales, and the borderlands.
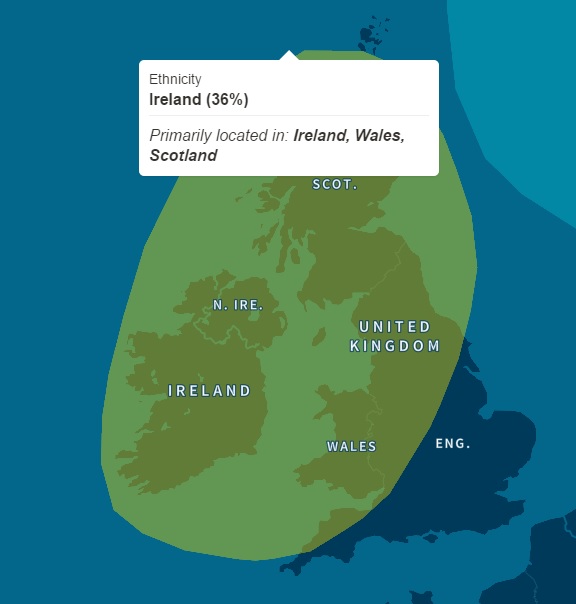
So, my father is almost entirely of Celtic stock. I guess that makes me a halfbreed Celt. I had expected a non-trivial amount of English and W. Euro ancestry, but I have only trace amounts of it.

As far as the 15% Scandinavian: According to AncestryDNA, “Scandinavian” shows up in a lot of British Islanders, and I’m no exception. It’s not “Viking” DNA necessarily, but it could be pretty deep ancestry that can’t be traced back “genealogically.” AFAIK, I have no recent Scandinavian surnames in my paternal lineage.
Maternal.
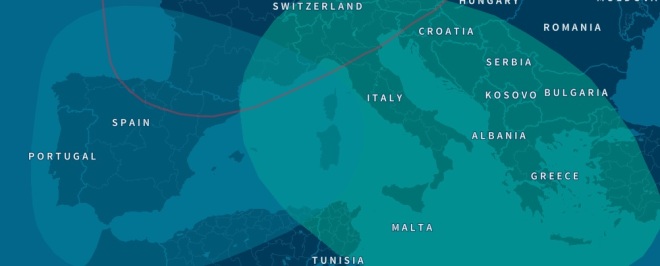
Southern European (Spanish/Italian) and Amerindian. What else did you expect from a Mexican?
Surprised to see the Southern European ancestry isn’t a neat Iberian chunk. It’s split all along the Mediterranean, from Spain to Greece. AncestryDNA isn’t great at figuring out Southern European ancestry, particularly from the Iberian peninsula (see the bar graph accuracy rates above—only 50% for Iberia!).
16-19% confidence range for the Native American ancestry. There are tools to locate that ancestry into “tribal” regions, so it’ll be interesting to determine in the coming months if it’s Mayan or Aztecan. Almost certainly the latter, given the region in which my recent-ish maternal ancestors lived:
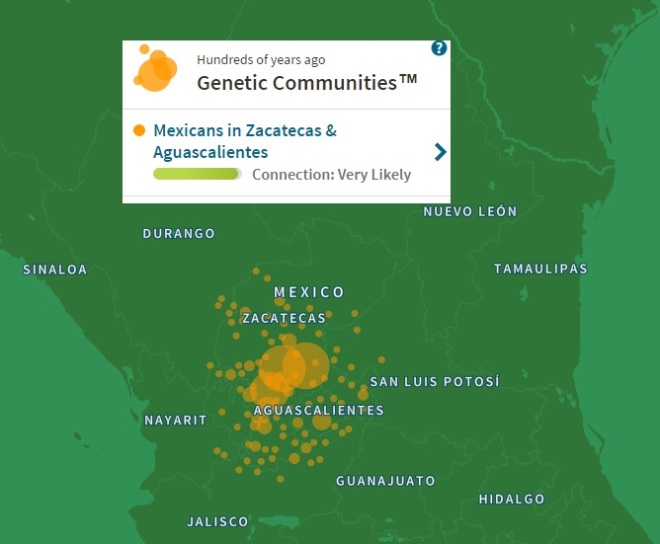
Central Mexico. Aguascalientes and Zacatecas. Far too north for the Mayans. Zacatecas comes from the Aztec word zacatl. Doesn’t mean my native ancestors were Aztec. That would be bad ass, but they just as likely could have been from the less civilized nomadic tribes the Aztecs called chichimeca, or barbarians.
The fact that my recent-ish Mexican ancestors are from Zacatecas and Aguascalientes fits well with my family history. Like many third and fourth generation Mexicans, my greats and grandparents came over in the 1910s and 1920s, during the Mexican Revolution. And, indeed, Zacatecas/Aguascalientes was the site of some of the Revolution’s most brutal fighting and was thus a prime source of origin for early 20th century Mexican immigrants.
Also, according to Wikipedia, San Luis Potosi, which is right next door to Zacatecas, is home to a non-trivial number of Italians. This might explain why my Southern Euro ancestry has an Italian component. Cross-state dalliances.
On the same Italian note, Ancestry provides you with cousin matches out to the sixth degree, for people who have also taken the test and appear to be related to you. Popping up in my matches are several people from the Italo-Mexican region of San Luis Potosi! Fourth and fifth cousins, extremely high probability. Only one of them has a picture; I won’t post it here, but she looks very Italian, not at all mestizo.
There’s some African and Middle Eastern noise, which, if legit, certainly comes from my mother’s side.

On average (again, per Analabha Basu et al.), Mexicans exhibit a small amount—roughly 4%—of African ancestry, a legacy of slavery sur de la frontera. Makes sense that a tiny amount would end up in my maternal lineage.
The Middle Eastern trace is probably a pulse from the Old World (Je Suis Charles Martel). It’s possible the M.E. trace could have sperm’ed or egg’ed its way into my lineage in Mexico, but since Lebanese and other Arabs didn’t start arriving in Mexico until the late 19th century, I doubt that’s the case.
Raw data.
This is just the beginning. I’ve downloaded my 700,000 SNPs and indels and am looking forward to uploading the data to other tools to match against other databases. I’ll also be looking for ways these genetic testing algorithms might be valuable for analysis of large textual data sets.